English | MP4 | AVC 1280×720 | AAC 44KHz 2ch | 29 lectures (4h 33m) | 1.53 GB
Deep Dive into Transformer Mathematics: From Tokenization to Multi-Head Attention to Masked Language Modeling & Beyond
Welcome to the Mathematics of Transformers, an in-depth course crafted for those eager to understand the mathematical foundations of large language models like GPT, BERT, and beyond. This course delves into the complex mathematical algorithms that allow these sophisticated models to process, understand, and generate human-like text. Starting with tokenization, students will learn how raw text is converted into a format understandable by models through techniques such as the WordPiece algorithm. We’ll explore the core components of transformer architectures—key matrices, query matrices, and value matrices—and their roles in encoding information. A significant focus will be on the mechanics of the attention mechanism, including detailed studies of multi-head attention and attention masks. These concepts are pivotal in enabling models to focus on relevant parts of the input data, enhancing their ability to understand context and nuance. We will also cover positional encodings, essential for maintaining the sequence of words in inputs, utilizing cosine and sine functions to embed the position information mathematically. Additionally, the course will include comprehensive insights into bidirectional and masked language models, vectors, dot products, and multi-dimensional word embeddings, crucial for creating dense representations of words. By the end of this course, participants will not only master the theoretical underpinnings of transformers but also gain practical insights into their functionality and application. This knowledge will prepare you to innovate and excel in the field of machine learning, placing you among the top echelons of AI engineers and researchers
What you’ll learn
- Mathematics Behind Large Language Models
- Positional Encodings
- Multi Head Attention
- Query, Value and Key Matrix
- Attention Masks
- Masked Language Modeling
- Dot Products and Vector Alignments
- Nature of Sine and Cosine functions in Positional Encodings
- How models like ChatGPT work under the hood
- Bidirectional Models
- Context aware word representations
- Word Embeddings
- How dot products work
- Matrix multiplication
- Programatically Create tokens
Table of Contents
Tokenization and Multidimensional Word Embeddings
1 Introduction to Tokenization
2 Tokenization in Depth
3 Encoding Tokens
4 Programatically Understanding Tokenizations
5 BERT vs. DistilBERT
6 Embeddings in a Continuous Vector Space
Positional Encodings
7 Introduction to Positional Encodings
8 How Positional Encodings Work
9 Understanding Even and Odd Indicies with Positional Encodings
10 Why we Use Sine and Cosine Functions for Positional Encodings
11 Understanding the Nature of Sine and Cosine Functions
12 Visualizing Positional Encodings in Sine and Cosine Graphs
13 Solving the Equations to get the Positional Encodings
Attention Mechanism and Transformer Architecture
14 Introduction to Attention Mechanisms
15 Query, Key, and Value Matrix
16 Getting started with our Step by Step Attention Calculation
17 Calculating Key Vectors
18 Query Matrix Introduction
19 Calculating Raw Attention Scores
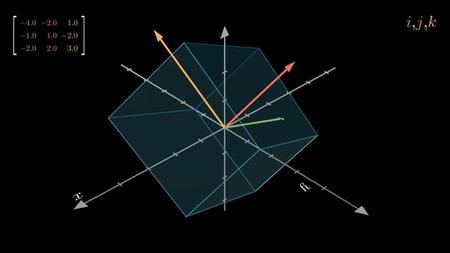
20 Understanding the Mathematics behind Dot products and Vector Alignment
21 Visualising Raw Attention Scores in 2 Dimensions
22 Converting Raw Attention Scores to Probability Distributions with Softmax
23 Normalisation and Scaling
24 Understanding the Value Matrix and Value Vector
25 Calculating the Final Context Aware Rich Representation for the word river
26 Understanding the Output
27 Understanding Multi Head Attention
28 Multi Head Attention Example, and Subsequent layers
29 Masked Language Modeling
Resolve the captcha to access the links!